Компонент String
Дата обновления перевода 2023-08-25
Компонент String
Компонент String предоставляет API, ориентированный на один объект, для работы с треями "модульными системами" строк: байтами, кодовыми точками и графемами.
Установка
1
$ composer require symfony/stringNote
Если вы устанавливаете этот компонент вне приложения Symfony, вам нужно
подключить файл vendor/autoload.php в вашем коде для включения механизма
автозагрузки классов, предоставляемых Composer. Детальнее читайте в
этой статье.
Что такое String?
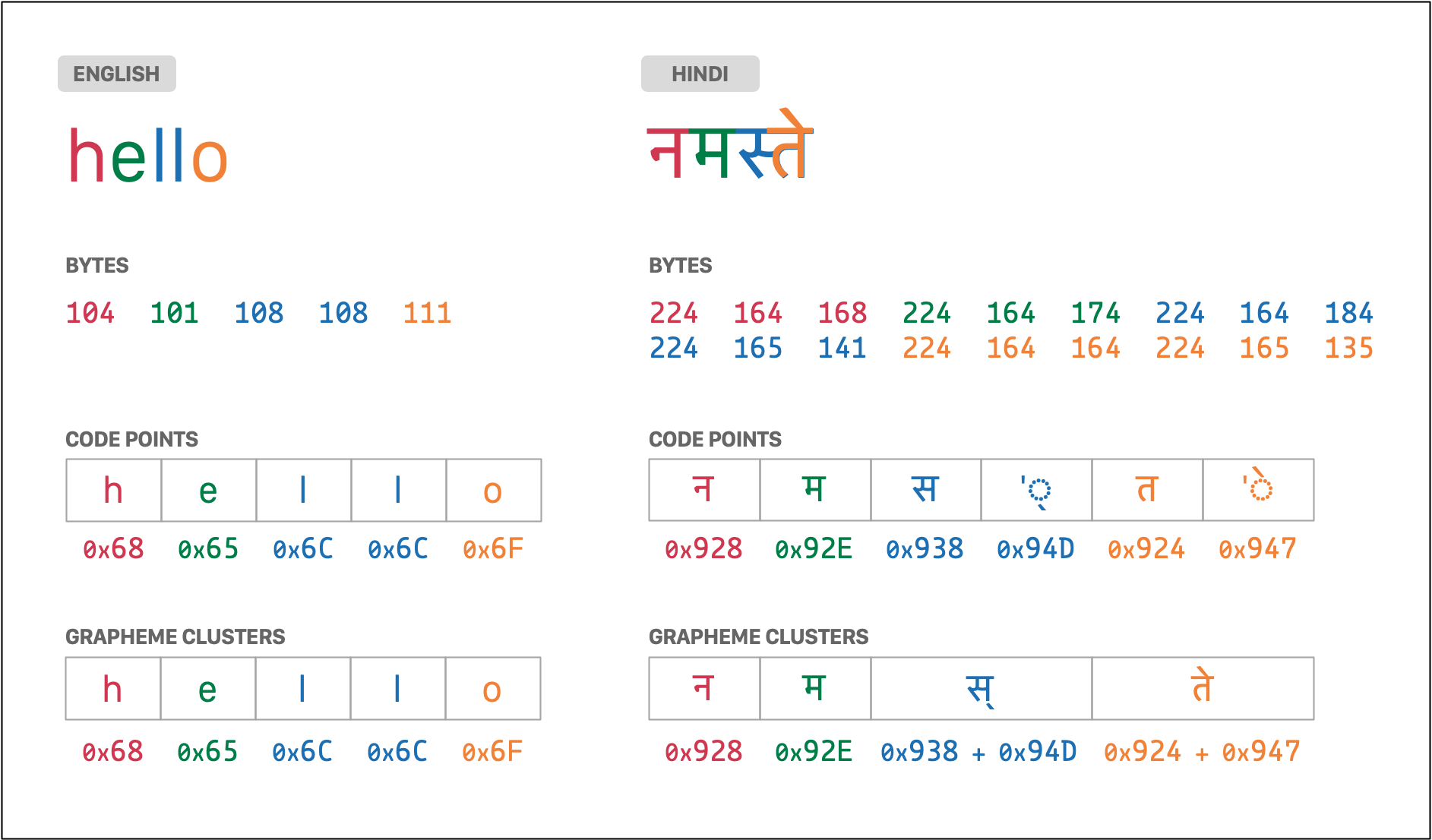
Вы можете пропустить этот раздел, если вы уже знаете, что такое "кодовая точка" или "графема" в контексте обработки строк. Если нет, то прочтите этот раздел, чтобы изучить терминологию, используемую данным компонентом.
Языки, вроде английского, требуют очень ограниченного набора знаков и символов для отображения любого содержания. Каждая строка - это набор знаков (букв или символов), которые могут быть зашифрованы даже с наиболее ограниченными стандартами (например, ASCII).
Однако, другие языки требуют тысячи знаков для отображения своего содержания. Им необходимы сложные стандарты шифрования вроде Юникод и концепции типа "знак" больше не имеют смысла. Вместо этого, вам нужно будет сталкиваться с такими терминами:
- Кодовые точки: это элементарная единица информации. Строка - это серия кодовых
точек. Каждая кодовая точка - это число, значение которого предоставляется стандартом
Юникод. Например, английская буква
A- это кодовая точкаU+0041, а японская канаの- это кодовая точкаU+306E. - Графемы: это последовательность одной или более кодовых точек, которые отображаются
в виде единой графической единицы. Например, испанская буква
ñ- это графема, содержащая две кодовые точки:U+006E=n("маленькая буква N латиницей") +U+0303=◌̃("комбинирующая тильда"). - Байты: реальная информация, хранящаясь в содержании строки. Каждая кодовая точка может требовать один или более байтов хранения в зависимости от используемого стандарта (UTF-8, UTF-16, и т.д.).
Следующее изображение отображает байты, кодовые точки и графемы для одного и того
же слова, написанного на английском (hello), и хинди (नमस्ते):
Использование
Создайте новый объект типа ByteString, CodePointString или UnicodeString, передайте содержание строки как его аргументы, а затем используйте объектно-ориентированный API для работы с этими строками:
1 2 3 4 5 6 7 8 9 10 11 12
use Symfony\Component\String\UnicodeString;
$text = (new UnicodeString('This is a déjà-vu situation.'))
->trimEnd('.')
->replace('déjà-vu', 'jamais-vu')
->append('!');
// $text = 'This is a jamais-vu situation!'
$content = new UnicodeString('नमस्ते दुनिया');
if ($content->ignoreCase()->startsWith('नमस्ते')) {
// ...
}Справочник методов
Методы создания объектов строки
Для начала, вы можете создавать объекты, готовые для хранения строк как байтов, кодовых точек и графем со следующими классами:
1 2 3 4 5 6 7 8
use Symfony\Component\String\ByteString;
use Symfony\Component\String\CodePointString;
use Symfony\Component\String\UnicodeString;
$foo = new ByteString('hello');
$bar = new CodePointString('hello');
// UnicodeString - наиболее используемый класс
$baz = new UnicodeString('hello');Используйте статический метод wrap(), чтобы инстанциировать более одного объекта строки:
1 2 3 4 5 6 7
$contents = ByteString::wrap(['hello', 'world']); // $contents = ByteString[]
$contents = UnicodeString::wrap(['I', '❤️', 'Symfony']); // $contents = UnicodeString[]
// используйте метод распаковки, чтобы создать инверсированную конверсию
$contents = UnicodeString::unwrap([
new UnicodeString('hello'), new UnicodeString('world'),
]); // $contents = ['hello', 'world']Если вы работаете со множеством объектов String, рассмотрите использование сокращений функций, чтобы сделать ваш код более емким:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
// функция b() создает байтовые строки
use function Symfony\Component\String\b;
// обе строчки одинаковы
$foo = new ByteString('hello');
$foo = b('hello');
// функция u() создает строки Юникода
use function Symfony\Component\String\u;
// обе строчки одинаковы
$foo = new UnicodeString('hello');
$foo = u('hello');
// функция s() создайте байтовую строку или строку Юникода
// depending on the given contents
use function Symfony\Component\String\s;
// создает объект ByteString
$foo = s("\xfe\xff");
// создает объект UnicodeString
$foo = s('अनुच्छेद');Также существуют специальные конструкторы:
1 2 3 4 5 6 7 8 9 10
// ByteString может создать произвольную строку заданной длины
$foo = ByteString::fromRandom(12);
// по умолчанию, произвольные строки используют символы A-Za-z0-9; вы можете ограничить
// используемые символы с помощью второго необязательного аргумента
$foo = ByteString::fromRandom(6, 'AEIOU0123456789');
$foo = ByteString::fromRandom(10, 'qwertyuiop');
// CodePointString и UnicodeString могут создать строку из кодовых точек
$foo = UnicodeString::fromCodePoints(0x928, 0x92E, 0x938, 0x94D, 0x924, 0x947);
// эквивалентно: $foo = new UnicodeString('नमस्ते');Методы преобразования объектов строки
Каждый объект строки может быть преобразован в два других типа объекта:
1 2 3 4 5 6 7 8
$foo = ByteString::fromRandom(12)->toCodePointString();
$foo = (new CodePointString('hello'))->toUnicodeString();
$foo = UnicodeString::fromCodePoints(0x68, 0x65, 0x6C, 0x6C, 0x6F)->toByteString();
// необязательный аргумент $toEncoding определяет шифрование целевой строки
$foo = (new CodePointString('hello'))->toByteString('Windows-1252');
// необязательный аргумент $fromEncoding определяет шифрование изначальной строки
$foo = (new ByteString('さよなら'))->toCodePointString('ISO-2022-JP');Если преобразование невозможно по какой-либо причине, вы получите InvalidArgumentException.
Также существует метод получения байтов, хранящихся в каком-то месте:
1 2 3 4 5 6 7
// ('नमस्ते' bytes = [224, 164, 168, 224, 164, 174, 224, 164, 184,
// 224, 165, 141, 224, 164, 164, 224, 165, 135])
b('नमस्ते')->bytesAt(0); // [224]
u('नमस्ते')->bytesAt(0); // [224, 164, 168]
b('नमस्ते')->bytesAt(1); // [164]
u('नमस्ते')->bytesAt(1); // [224, 164, 174]Методы, связанные с длиной и символами пробелов
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
// возвращает количество графем, кодовых точек или байтов заданной строки
$word = 'नमस्ते';
(new ByteString($word))->length(); // 18 (байтов)
(new CodePointString($word))->length(); // 6 (кодовых точек)
(new UnicodeString($word))->length(); // 4 (графем)
// некоторые символы требуют вдвое больше пространства, чем другие, для отображения при использовании
// моноширинного шрифта (например, в консоли). Этот метод возвращает общую длину, необходимую для
// отображения всего слова
$word = 'नमस्ते';
(new ByteString($word))->width(); // 18
(new CodePointString($word))->width(); // 4
(new UnicodeString($word))->width(); // 4
// если текст содержит несколько строчек, он возвращает максимальную длину всех строчек
$text = "<<<END
This is a
multiline text
END";
u($text)->width(); // 14
// возвращает TRUE только если строка является пустой (даже без сводоных пространств)
u('hello world')->isEmpty(); // false
u(' ')->isEmpty(); // false
u('')->isEmpty(); // true
// удаляет все свободные пространства (' \n\r\t\x0C') с начала до конца строки и заменяет два или
// более последовательных пробела внутри содержания на один
u(" \n\n hello \t \n\r world \n \n")->collapseWhitespace(); // 'hello world'Методы изменения регистра
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
// изменяет все графемы/кодовые точки на нижний регистр
u('FOO Bar')->lower(); // 'foo bar'
// при работе с разными языками, нижнего/верхнего регистра недостаточно
// тогда регистра три (нижний, верхний, заглавный), некоторые символы не имеют регистра,
// регистр чувствителен к контексту, локали и т.д.
// этот метод возвращает строку, которую вы можете использовать в нечувствительных к регистру сравнениях
u('FOO Bar')->folded(); // 'foo bar'
u('Die O\'Brian Straße')->folded(); // "die o'brian strasse"
// изменяет все графемы/кодовые точки на верхний регистр
u('foo BAR')->upper(); // 'FOO BAR'
// изменяет все графемы/кодовые точки на "заглавный регистр"
u('foo bar')->title(); // 'Foo bar'
u('foo bar')->title(true); // 'Foo Bar'
// изменяет все графемы/кодовые точки на camelCase
u('Foo: Bar-baz.')->camel(); // 'fooBarBaz'
// изменяет все графемы/кодовые точки на snake_case
u('Foo: Bar-baz.')->snake(); // 'foo_bar_baz'
// других регистров можно достичь, изменив методы. Например, PascalCase:
u('Foo: Bar-baz.')->camel()->title(); // 'FooBarBaz'Методы всех классов строк чувствительны к регистру по умолчанию. Вы можете выполнить
нечувствительные к регистру операции с помощью метода ignoreCase():
1 2
u('abc')->indexOf('B'); // null
u('abc')->ignoreCase()->indexOf('B'); // 1Методы добавления к началу и концу
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
// добавляет заданное содержание (одну или более строк) в начале/конце строки
u('world')->prepend('hello'); // 'helloworld'
u('world')->prepend('hello', ' '); // 'hello world'
u('hello')->append('world'); // 'helloworld'
u('hello')->append(' ', 'world'); // 'hello world'
// добавляет заданное содержание в начале строки (или удаляет его), чтобы гарантировать, что
// содержание начнается именно с этого
u('Name')->ensureStart('get'); // 'getName'
u('getName')->ensureStart('get'); // 'getName'
u('getgetName')->ensureStart('get'); // 'getName'
// этот метод похож, но работает с концом содержания, а не с началом
u('User')->ensureEnd('Controller'); // 'UserController'
u('UserController')->ensureEnd('Controller'); // 'UserController'
u('UserControllerController')->ensureEnd('Controller'); // 'UserController'
// возвращает все содержание, найденное до/после первого появления заданной строки
u('hello world')->before('world'); // 'hello '
u('hello world')->before('o'); // 'hell'
u('hello world')->before('o', true); // 'hello'
u('hello world')->after('hello'); // ' world'
u('hello world')->after('o'); // ' world'
u('hello world')->after('o', true); // 'o world'
// возвращает все содержание, найденное до/после последнего появления заданной строки
u('hello world')->beforeLast('o'); // 'hello w'
u('hello world')->beforeLast('o', true); // 'hello wo'
u('hello world')->afterLast('o'); // 'rld'
u('hello world')->afterLast('o', true); // 'orld'Методы заполнения и усечения
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
// делает строку той же длины, что и первый аргумент, добавляя заданную
// строку в начале, конце или по обе стороны строки
u(' Lorem Ipsum ')->padBoth(20, '-'); // '--- Lorem Ipsum ----'
u(' Lorem Ipsum')->padStart(20, '-'); // '-------- Lorem Ipsum'
u('Lorem Ipsum ')->padEnd(20, '-'); // 'Lorem Ipsum --------'
// повторяет заданную строку то количество раз, которое передано в аргументе
u('_.')->repeat(10); // '_._._._._._._._._._.'
// удаляет заданные символы (по умолчанию, свободные пространства) из строки
u(' Lorem Ipsum ')->trim(); // 'Lorem Ipsum'
u('Lorem Ipsum ')->trim('m'); // 'Lorem Ipsum '
u('Lorem Ipsum')->trim('m'); // 'Lorem Ipsu'
u(' Lorem Ipsum ')->trimStart(); // 'Lorem Ipsum '
u(' Lorem Ipsum ')->trimEnd(); // ' Lorem Ipsum'
// удаляет заданное содержание с начала/конца строки
u('file-image-0001.png')->trimPrefix('file-'); // 'image-0001.png'
u('file-image-0001.png')->trimPrefix('image-'); // 'file-image-0001.png'
u('file-image-0001.png')->trimPrefix('file-image-'); // '0001.png'
u('template.html.twig')->trimSuffix('.html'); // 'template.html.twig'
u('template.html.twig')->trimSuffix('.twig'); // 'template.html'
u('template.html.twig')->trimSuffix('.html.twig'); // 'template'
// при передаче массива префисков/суфиксов, усекается только первый найденный
u('file-image-0001.png')->trimPrefix(['file-', 'image-']); // 'image-0001.png'
u('template.html.twig')->trimSuffix(['.twig', '.html']); // 'template.html'Методы поиска и замены
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42
// проверяет, начинается/заканчивается ли строка с заданной строки
u('https://symfony.com')->startsWith('https'); // true
u('report-1234.pdf')->endsWith('.pdf'); // true
// проверяет, точно ли содержание строки соответствует заданному содержанию
u('foo')->equalsTo('foo'); // true
// проверяет, соответствует ли содержание строки заданному регулярному выражению
u('avatar-73647.png')->match('/avatar-(\d+)\.png/');
// result = ['avatar-73647.png', '73647']
// проверяет, содержит ли строка любую из заданных строк
u('aeiou')->containsAny('a'); // true
u('aeiou')->containsAny(['ab', 'efg']); // false
u('aeiou')->containsAny(['eio', 'foo', 'z']); // true
// находит местоположение первого обнаружения заданной строки
// (второй аргумент - местоположение, откуда начинается поиск, негативные
// значения имеют то же значение, что и в PHP-функциях)
u('abcdeabcde')->indexOf('c'); // 2
u('abcdeabcde')->indexOf('c', 2); // 2
u('abcdeabcde')->indexOf('c', -4); // 7
u('abcdeabcde')->indexOf('eab'); // 4
u('abcdeabcde')->indexOf('k'); // null
// находит местоположение последнего обнаружения заданной строки
// (второй аргумент - местоположение, откуда начинается поиск, негативные
// значения имеют то же значение, что и в PHP-функциях)
u('abcdeabcde')->indexOfLast('c'); // 7
u('abcdeabcde')->indexOfLast('c', 2); // 7
u('abcdeabcde')->indexOfLast('c', -4); // 2
u('abcdeabcde')->indexOfLast('eab'); // 4
u('abcdeabcde')->indexOfLast('k'); // null
// заменяет все обнаружения заданной строки
u('http://symfony.com')->replace('http://', 'https://'); // 'https://symfony.com'
// заменяет все обнаружения заданного регулярного выражения
u('(+1) 206-555-0100')->replaceMatches('/[^A-Za-z0-9]++/', ''); // '12065550100'
// вы можете передать вызываемое в качестве второго аргумента, чтобы выполнить продвинутые замены
u('123')->replaceMatches('/\d/', function (string $match): string {
return '['.$match[0].']';
}); // result = '[1][2][3]'Методы объединения, разделения, усечения и реверса
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
// использует строку в качестве "клея" для объединения всех заданных строк
u(', ')->join(['foo', 'bar']); // 'foo, bar'
// разбивает строку на части, используя заданный разделитель
u('template_name.html.twig')->split('.'); // ['template_name', 'html', 'twig']
// вы можете установить макисмальное количество частей в качестве второго аргумента
u('template_name.html.twig')->split('.', 2); // ['template_name', 'html.twig']
// возвращает подстроку, которая начинается с первого аргумента и имеет длину второго
// необязательного аргумента (негативные значения имеют то же значение, что и в PHP-функциях)
u('Symfony is great')->slice(0, 7); // 'Symfony'
u('Symfony is great')->slice(0, -6); // 'Symfony is'
u('Symfony is great')->slice(11); // 'great'
u('Symfony is great')->slice(-5); // 'great'
// уменьшает строку до длины, заданной в качестве аргумента (если она длиннее)
u('Lorem Ipsum')->truncate(3); // 'Lor'
u('Lorem Ipsum')->truncate(80); // 'Lorem Ipsum'
// второй аргумент - символ(ы), добавленные, когда строка урезается
// (общая длина включает в себя длину этого(их) символа(ов))
u('Lorem Ipsum')->truncate(8, '…'); // 'Lorem I…'
// если третий аргумент - false, последнее слово до обрезания остается, даже
// если это создает строку, больше описанной длины
u('Lorem Ipsum')->truncate(8, '…', false); // 'Lorem Ipsum'1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// разбивает строку на строчки заданной длины
u('Lorem Ipsum')->wordwrap(4); // 'Lorem\nIpsum'
// по умолчанию разбивает по свободным пространствам; передайте TRUE, чтобы разбивать независимо от этого
u('Lorem Ipsum')->wordwrap(4, "\n", true); // 'Lore\nm\nIpsu\nm'
// заменяет часть строки на заданное содержание:
// второй аргумент - местоположение, с которого начинается замена;
// третий аргумент - количество графем/кодовых точек, удаленных из строки
u('0123456789')->splice('xxx'); // 'xxx'
u('0123456789')->splice('xxx', 0, 2); // 'xxx23456789'
u('0123456789')->splice('xxx', 0, 6); // 'xxx6789'
u('0123456789')->splice('xxx', 6); // '012345xxx'
// разбивает строку на части длиной, заданной аргументом
u('0123456789')->chunk(3); // ['012', '345', '678', '9']
// реверсирует порядок содержания строки
u('foo bar')->reverse(); // 'rab oof'
u('さよなら')->reverse(); // 'らなよさ'Методы, добавленные ByteString
Эти методы доступны только для объектов ByteString:
1 2 3
// возвращает TRUE, если содержание строки является валидным содержанием UTF-8
b('Lorem Ipsum')->isUtf8(); // true
b("\xc3\x28")->isUtf8(); // falseМетоды, добавленные CodePointString и UnicodeString
Эти методы доступны только для объектов CodePointString и UnicodeString:
1 2 3 4 5 6 7 8 9 10 11
// транслитерирует любоую строку в латинский алфавит, определенный шифрованием ASCII
// (не используйте этот метод для создания слаггера, так как данный компонент уже предоставляет
// слаггер, как объясняет дальше в статье)
u('नमस्ते')->ascii(); // 'namaste'
u('さよなら')->ascii(); // 'sayonara'
u('спасибо')->ascii(); // 'spasibo'
// возвращает массив с кодовой точкой или точками, хранящимися в заданном местоположении
// (кодовые точки 'नमस्ते' графемы = [2344, 2350, 2360, 2340]
u('नमस्ते')->codePointsAt(0); // [2344]
u('नमस्ते')->codePointsAt(2); // [2360]Эквивалентность Юникода - это спецификация стандарта Юникод, по которой разные
последовательности кодовых точек предоставляют один и тот же знак. Например,
шведская буква å может быть одной кодовой точкой (U+00E5 = "маленькая латинская
буква А с кольцом над ней") или последовательностью двух кодовых точек (U+0061 =
"маленькая латинская буква A" + U+030A = "комбинация с кольцом сверху"). Метод
normalize() позволяет выбрать режим нормализации:
1 2 3 4 5 6
// эти зашифровывают букву как одну кодовую точку: U+00E5
u('å')->normalize(UnicodeString::NFC);
u('å')->normalize(UnicodeString::NFKC);
// эти зашифровывают букву как две кодовые точки: U+0061 + U+030A
u('å')->normalize(UnicodeString::NFD);
u('å')->normalize(UnicodeString::NFKD);Лениво загружаемые строки
Иногда создание строки с помощью методов, представленных в предыдущих разделах, не является оптимальным. Например, рассмотрим значение хеша, для получения которого требуются определенные вычисленя и которое в итоге может не использоваться.
В таких случаях лучше использовать класс LazyString, позволяющий хранить строку, значение которой генерируется только тогда, когда она нужна:
1 2 3 4 5 6 7 8 9
use Symfony\Component\String\LazyString;
$lazyString = LazyString::fromCallable(function (): string {
// Вычислить значение строки...
$value = ...;
// Затем вернуть финальное значение
return $value;
});Обратный вызов будет выполнен только тогда, когда значение ленивой строки будет
запрошено во время выполнения программы. Вы также можете создавать ленивые строки
из объекта Stringable:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
class Hash implements \Stringable
{
public function __toString(): string
{
return $this->computeHash();
}
private function computeHash(): string
{
// Вычислить значение хеша с потенциально сложной обработкой
$hash = ...;
return $hash;
}
}
// Затем создать ленивую строку из этог хеша, что вызовет вычисление
// хеша только если это потребуется
$lazyHash = LazyString::fromStringable(new Hash());Слаггер
В некоторых контекстах, вроде URL и названий файлов/каталогов, небезопасно использовать любой символ Юникода. Слаггер преобразует заданную строку в другую строку, которая содержит только безопасные символы ASCII:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
use Symfony\Component\String\Slugger\AsciiSlugger;
$slugger = new AsciiSlugger();
$slug = $slugger->slug('Wôrķšƥáçè ~~sèťtïñğš~~');
// $slug = 'Workspace-settings'
// вы также можете передать массив с дополнительными заменами символов
$slugger = new AsciiSlugger('en', ['en' => ['%' => 'percent', '€' => 'euro']]);
$slug = $slugger->slug('10% or 5€');
// $slug = '10-percent-or-5-euro'
// если для вашей локали не существует отображения символа (например, 'en_GB'), то будет использовано
// отображение символа родительской локали (т.e. 'en')
$slugger = new AsciiSlugger('en_GB', ['en' => ['%' => 'percent', '€' => 'euro']]);
$slug = $slugger->slug('10% or 5€');
// $slug = '10-percent-or-5-euro'
// для более динамичных замен, передайте замыкание PHP вместо массива
$slugger = new AsciiSlugger('en', function (string $string, string $locale): string {
return str_replace('❤️', 'love', $string);
});Разделитель между словами - по умолчанию дефис (-), но вы можете определить другой
разделить как второй аргумент:
1 2
$slug = $slugger->slug('Wôrķšƥáçè ~~sèťtïñğš~~', '/');
// $slug = 'Workspace/settings'Слаггер транслитерирует изначальную строку в латиницу до того, как применять любые другие преобразования. Локаль изначальной строки определяется автоматически, но вы можете ясно определить ее:
1 2 3 4 5
// сообщает слаггеру транслитерировать с корейского языка
$slugger = new AsciiSlugger('ko');
// вы можете переопределить локаль в качестве третьего необязательного параметра slug()
$slug = $slugger->slug('...', '-', 'fa');В приложении Symfony, вам не нужно создавать слаггер самостоятельно. Благодаря автомонтированию сервисов, вы можете внедрить слаггер с подсказкой в аргументе сервис-конструктора с помощью SluggerInterface. Локаль внедренного слаггера будет той же, что и локаль запроса:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
use Symfony\Component\String\Slugger\SluggerInterface;
class MyService
{
public function __construct(
private SluggerInterface $slugger,
) {
}
public function someMethod(): void
{
$slug = $this->slugger->slug('...');
}
}Эмоджи слага
6.2
Функция транслитерации эмоджи была представлена в Symfony 6.2.
Вы можете преобразовать любые эмоджи в их текстовое представление:
1 2 3 4 5 6 7 8 9 10
use Symfony\Component\String\Slugger\AsciiSlugger;
$slugger = new AsciiSlugger();
$slugger = $slugger->withEmoji();
$slug = $slugger->slug('a 😺, 🐈⬛, and a 🦁 go to 🏞️', '-', 'en');
// $slug = 'a-grinning-cat-black-cat-and-a-lion-go-to-national-park';
$slug = $slugger->slug('un 😺, 🐈⬛, et un 🦁 vont au 🏞️', '-', 'fr');
// $slug = 'un-chat-qui-sourit-chat-noir-et-un-tete-de-lion-vont-au-parc-national';Если вы хотите использовать конкретную локаль для эмоджи, или использовать скоращённые
коды с GitHub или Slack, используйте первый аргумент метода withEmoji():
1 2 3 4 5 6 7
use Symfony\Component\String\Slugger\AsciiSlugger;
$slugger = new AsciiSlugger();
$slugger = $slugger->withEmoji('github'); // или "en", или "fr" и т.д.
$slug = $slugger->slug('a 😺, 🐈⬛, and a 🦁');
// $slug = 'a-smiley-cat-black-cat-and-a-lion';Инфлектор
В некоторых случаях, вроде генерирования и интроспекции кода, вам нужно
преобразовывать слова в/из множественного/единственное число. Например, чтобы
узнать свойство, асооциированное с методом adder, вы должны выполнить преобразование
из множественного (метод addStories()) в единственное (свойство $story).
Большинство человеческих языков имеют простые правила множественных чисел, но в то
же время они определяют много исключений. Например, общее правило в английском языке
- добавлять s в конце слова (book -> books), но существует множество
исключений даже для распространенных слов (woman -> women, life -> lives,
news -> news, radius -> radii, и т.д.)
Этот компонент предоставляет класс EnglishInflector, чтобы уверенно преобразовывать английские слова в/из единственное/множественное число:
1 2 3 4 5 6 7 8 9 10 11
use Symfony\Component\String\Inflector\EnglishInflector;
$inflector = new EnglishInflector();
$result = $inflector->singularize('teeth'); // ['tooth']
$result = $inflector->singularize('radii'); // ['radius']
$result = $inflector->singularize('leaves'); // ['leaf', 'leave', 'leaff']
$result = $inflector->pluralize('bacterium'); // ['bacteria']
$result = $inflector->pluralize('news'); // ['news']
$result = $inflector->pluralize('person'); // ['persons', 'people']Значение, возвращенное обоими методами, всегда являетя массивом, так как иногда невозможно определить уникальную единственную/множественную форму заданного слова.
Note
Symfony также предоставляет FrenchInflector и InflectorInterface, если вам нужно реализовать собственный инфлектор.